FaceForensics++:
Learning to Detect Manipulated Facial Images
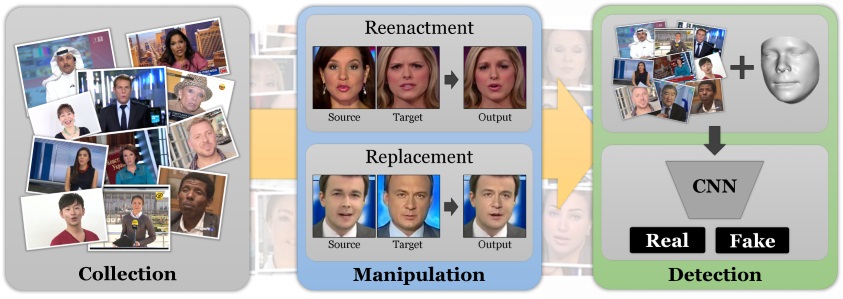
The rapid progress in synthetic image generation and manipulation has now come to a point where it raises significant concerns for the implications towards society. At best, this leads to a loss of trust in digital content, but could potentially cause further harm by spreading false information or fake news. This paper examines the realism of state-of-the-art image manipulations, and how difficult it is to detect them, either automatically or by humans. To standardize the evaluation of detection methods, we propose an automated benchmark for facial manipulation detection. In particular, the benchmark is based on DeepFakes, Face2Face, FaceSwap and NeuralTextures as prominent representatives for facial manipulations at random compression level and size. The benchmark is publicly available and contains a hidden test set as well as a database of over 1.8 million manipulated images. This dataset is over an order of magnitude larger than comparable, publicly available, forgery datasets. Based on this data, we performed a thorough analysis of data-driven forgery detectors. We show that the use of additional domain specific knowledge improves forgery detection to unprecedented accuracy, even in the presence of strong compression, and clearly outperforms human observers.
Dataset Access
If you would like to download the FaceForensics and FaceForensics++ datasets, please fill out this google form and, once accepted, we will send you the link to our download script.
Update: We are also hosting the DeepFakes Detection Dataset which includes various high quality scenes of multiple actors which have been manipulated using DeepFakes. The dataset was donated by Google/Jigsaw to support the community effort on detecting manipulated faces. To obtain this dataset please use the google form provided above.
Benchmark
We are offering an automated benchmark for facial manipulation detection on the presence of compression based on our manipulation methods. If you are interested to test your approach on unseen data, visit it here.
Source Code & Contact
For more information about our code, visit our github or contact us under faceforensics@googlegroups.com.